
互联网协议-Chapter 2 Transport Layer
Chapter 2 Transport Layer
提纲
[TOC]
Application layer
1. Application layer
application layer 不是本课重点,所以只用几页ppt简介(高编里重点讲了)
This is the layer you (mostly) work with as a programmer.
At the application layer the “network” is abstracted away and you access a stream of data that arrives at a “socket”.通过套接字socket访问网络层数据流
Different applications have different formats:
• HTTP (Hypertext transfer protocol) world-wide web
• FTP (File transfer protocol) moving data
• SMTP (Send Mail transfer protocol) sending email
• IMAP (Internet message access protocol) receiving email
Sockets
process sends/receives messages to/from its socket
进程通过socket传递信息
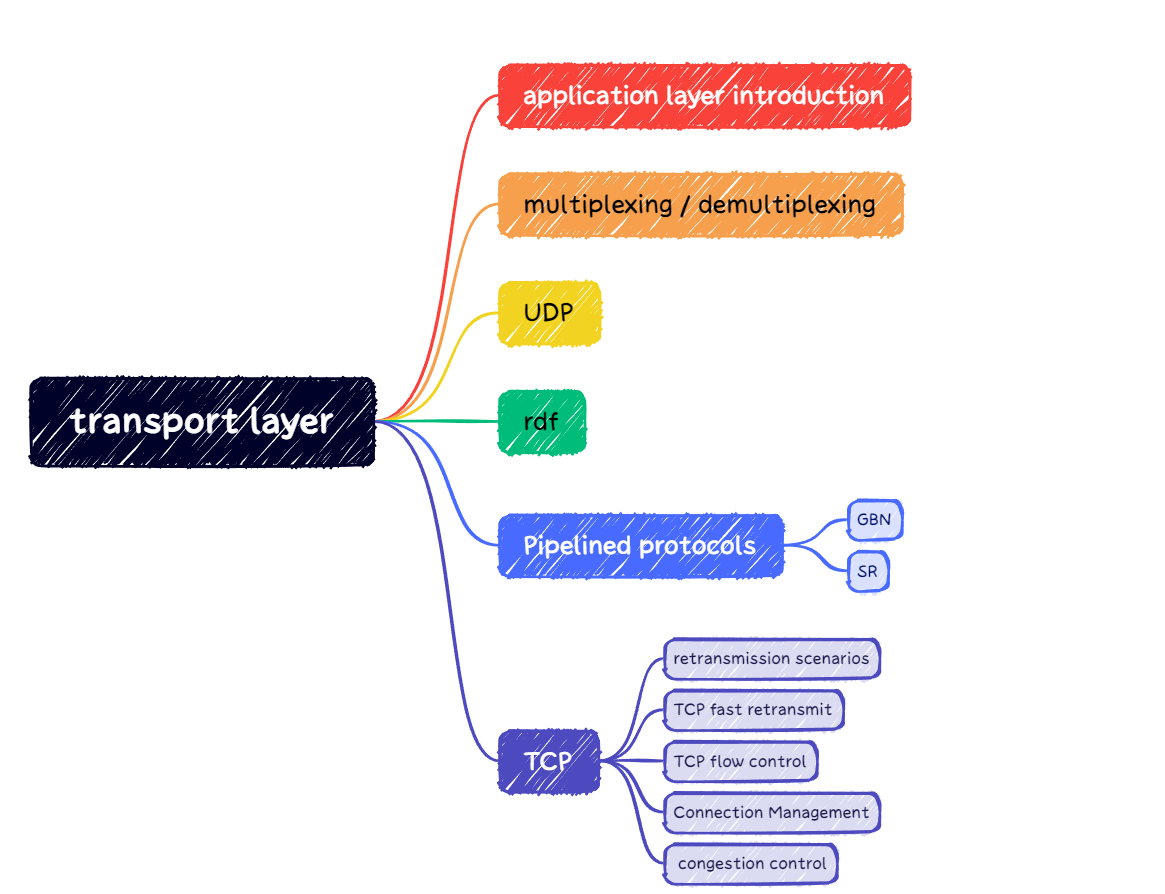
- 套接字 <=> 门户
发送进程将报文推出门户,发送进程依赖于传输层设施在另外一侧的门将报文交付给接受进程
接收进程从另外一端的门户收到报文(依赖于传输层设施)
Addressing processes
进程寻址
to receive messages, process must have identifier
host device has unique 32- bit IP address
identifier includes both IP address and port numbers(进程端口号) associated with process on host.
example port numbers:
• HTTP server: 80
• mail server: 25
Q: does IP address of host on which process runs suffice for identifying the process?
A: no, many processes can be running on same host(一个主机多个进程)
4 different addresses in TCP/IP
Physical address Layer 2
• ==Also known as the link address, is the address of a node as defined by its LAN or WAN==
物理地址称为链路地址,是由接点所在的局域网或广域网为该结点指定的地址。
Logical address Layer 3 (32-bit , IPv4 128-bit IPv6)
• Logical (IP) addresses are for universal communications( 全局通信 )that are independent of underlying physical networks 与底层物理网络无关
Port address Layer 4 (16-bit)
• Port addresses differentiate different processes
**Application-specific address Layer 7 **特定应用地址
• Some applications have user-friendly addresses that are designed for that specific application, such as email address, URL.
有些应用程序具有专门为其量身定做的用户友好型地址。
application protocol defines
应用层协议定义了在不同端系统如何传递报文
1. types of messages exchanged
• e.g., request, response
2. message syntax
what fields(字段) in messages & how fields are delineated
3. message semantics (语义)
meaning of information in fields
4. rules for when and how processes send & respond to messages
open protocols:
defined in RFCs (request for comments) 由RFC文档定义
allows for interoperability 允许互操作
e.g., HTTP (web), SMTP (email)
proprietary protocols专用(私有)协议:
e.g., Skype
translation layer
provide logical communication between app processes running on different hosts
send side: breaks app messages into segments, passes to network layer
rcv side: reassembles segments into messages, passes to app layer
network layer: logical communication between hosts
transport layer: logical communication between processes
Multiplexing/demultiplexing
Multiplexing (Mux):
• Combining several streams of data into a single stream.
• Example – your phone is browsing the web, refreshing your email, connecting to WeChat at the same time. All these connections are sent over the same link.
Demultipliexing (Demux)
A stream of data is separated out into its individual components.
The stream of packets the phone received is split up and sent to the appropriate program for web, email, wechat.
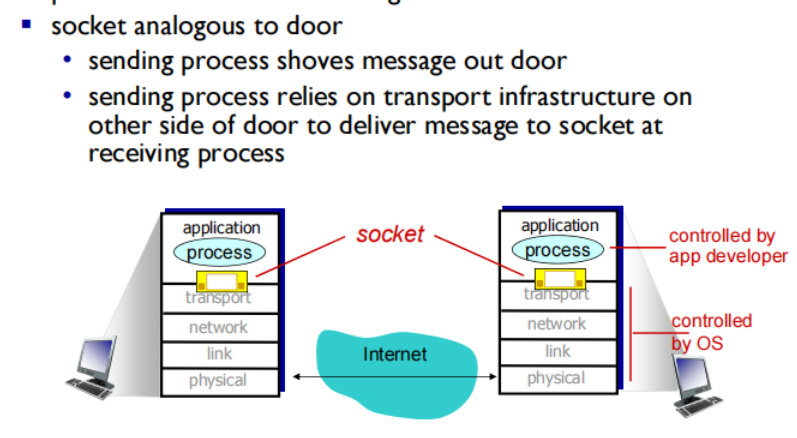
multiplexing at sender: handle data from multiple sockets, add transport header (later used for demultiplexing, 提供进程的信息:IP+port)
demultiplexing at receiver: use header info to deliver received segments to correct socket
How demultiplexing works
host receives IP datagrams(数据报:第三层的packet)
• each datagram has source IP address, destination IP address
• each datagram carries one transport-layer segment
• each segment has source, destination port number
无论tcp udp 都有source port and destination port(当然还有其它字段)
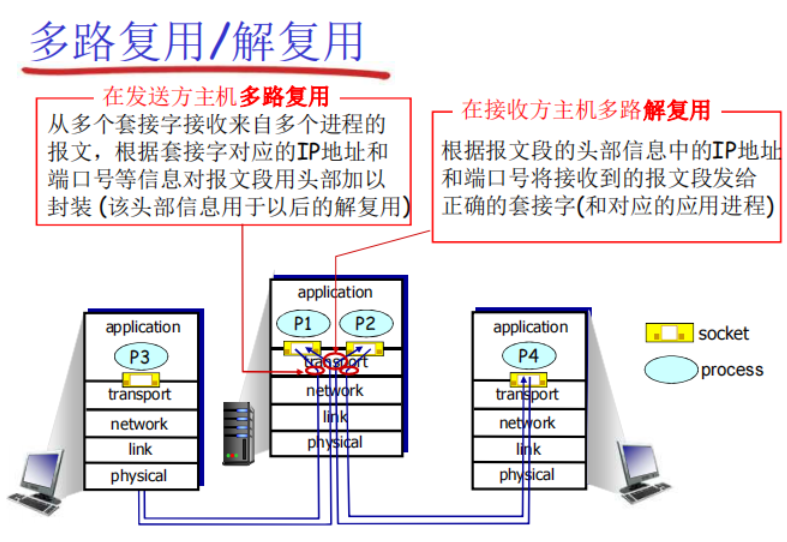
- host uses IP addresses & port numbers to direct(引导) segment to appropriate socket
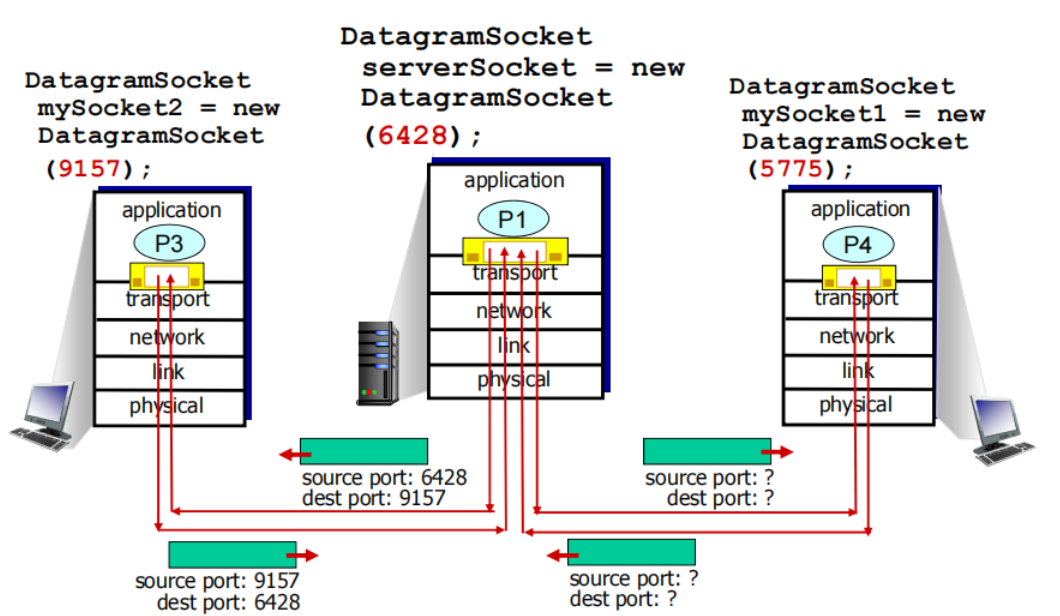
Connectionless demux
UDP socket identified by 2-tuple
• checks destination port # in segment
• directs UDP segment to socket with that port #
如果两个不同源IP地址/源端口号的数据报,但是有相同的目标IP地址和端口号,则被定位到相同的套接字(一个UDP套接字是被目标IP与目标port唯一标识的)
IP datagrams with same dest. port #, but different source IP addresses and/or source port numbers will be directed to same socket at dest 具备相同目标IP地址和目标端口号,即使是源IP地址或/且源端口号不同的IP数据报,将会被传到相同的目标UDP套接字上
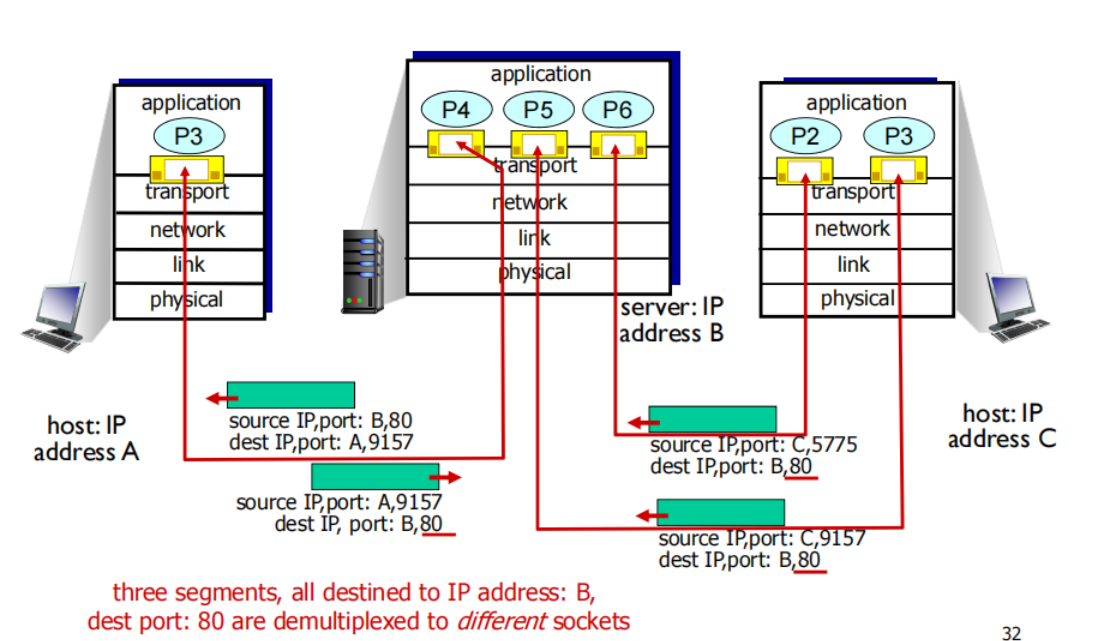
Connection-oriented demux
TCP socket identified by 4-tuple
( demux: receiver uses all four values to direct segment to appropriate socket):
• source IP address
• source port number
• dest IP address
• dest port number
TCP socket是由四元组(目标ip 目标port 源IP 源port)唯一确定的
一个port可以有多个进程
web servers have different sockets for each connecting client
server host may support many simultaneous TCP sockets:
- web servers have different sockets for each connecting client
- 所以每有一个客户端连接,就新建一个process(p4 p5 p6)
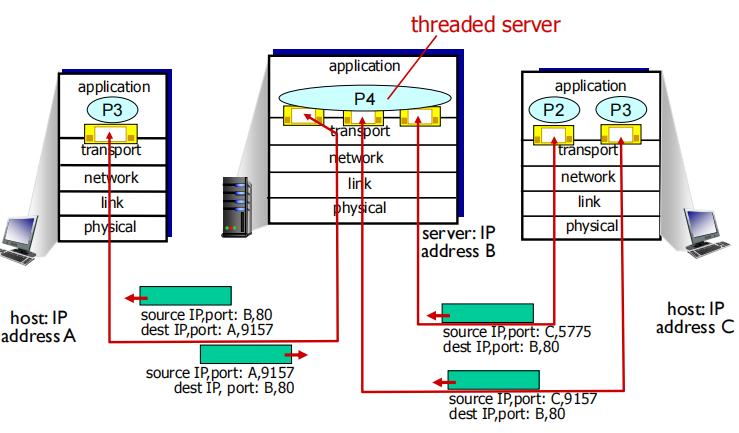
但是进程与socket并不是一一对应关系,当一个进程包含多个thread时可能对应多个socket
Typical port numbers for applications
背一下,可能考
Port 80: Standard HTTP (Hypertext Transfer Protocol – browse the web
Port 22: ssh (secure shell) log in from remote computer
Port 25: SMTP (simple mail transfer protocol) – send mail via this host
Port 143: IMAP (Internet Message Access Protocol) – read your email
Port 443: HTTPS (secure HTTP) browse the web securely
UDP: User Datagram Protocol
Simplest usable Internet transport protocol
“best effort”尽力而为 service, UDP segments may be:
• lost
• delivered out-of-order to app 失序
connectionless:
• no “handshaking” between UDP sender, receiver (can send immediately without asking first)
每个UDP报文段都被独立地处理handled independently
UDP use:
streaming multimedia(流媒体) apps (loss tolerant, rate sensitive)
DNS
NMP
reliable transfer over UDP: 用udp实现可靠传输的方法
- add reliability at application layer
- application-specific error recovery!应用特定的差错恢复
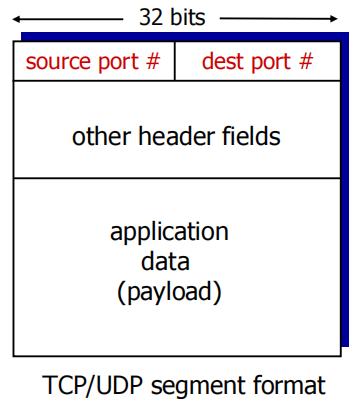
多了length 和checksum
头部一共8byte
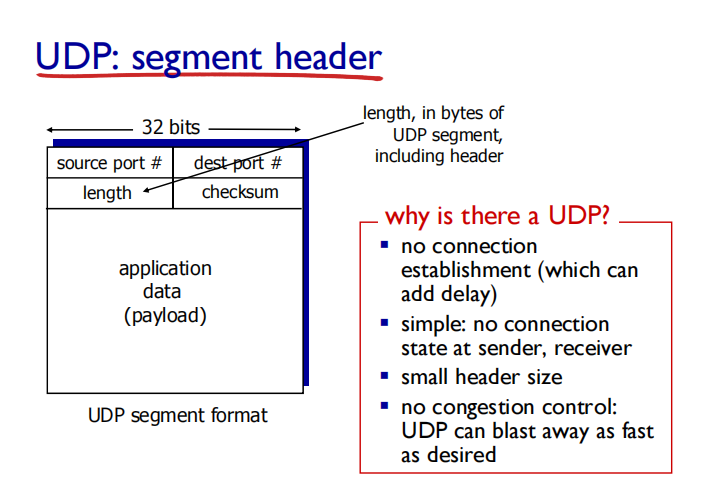
为什么要有UDP(UDP 好处)?
不建立连接 (会增加延时)
简单:在发送端和接收端没有连接状态
报文段的头部很小(开销小)也就是报文段可以占更多空间
无拥塞控制和流量控制:UDP可以尽可能快的发送报文段
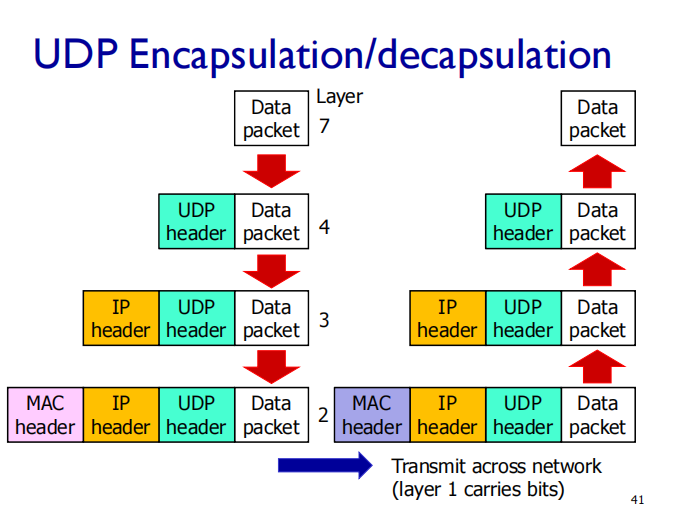
UDP checksum
Goal: detect “ errors ”(flipped bits 比特翻转)
sender:
treat segment contents, including header fields, as sequence of 16-bit integers.
分成多个十六比特序列
checksum: addition of all of segment contents(各数据段相加回卷反码)
sender puts checksum value into UDP checksum field 把结果放到检验和区域
receiver:
compute checksum of received segment(先用segment compute)
check if computed checksum equals checksum field value: (再和发来的checksum比)
不相同一定传输有错,相同不一定没错
• NO - error detected
• YES - no error detected.
还是有可能有错误:checksum传输错误,payload也错误,并且最后比对结果一致
Principles of reliable data transfer (rdf)
可靠数据传输原理
将较低层直接视为不可靠信道(在不可可靠的下层协议基础上实现reliable data transfer)
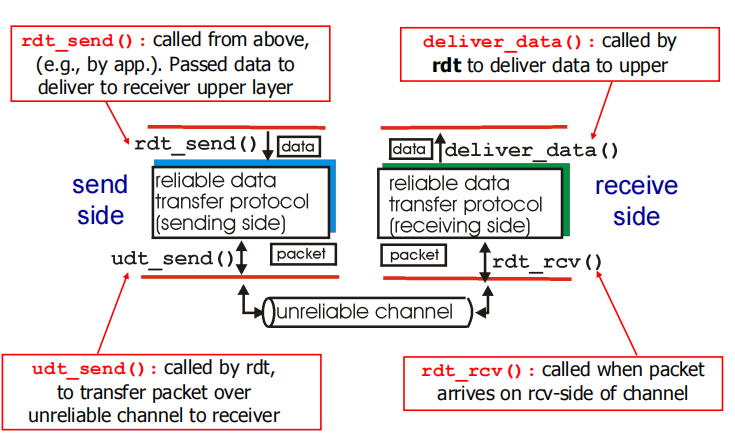
**rdt_send():**发送方上层调用,将数据发往接收方application layer
udt_send(): rdt调用将数据发给udt(下层)
**rdt_rcv():**数据到达接收方
**deliver_data():**rdt调用将数据交付更高层
consider only unidirectional data transfer(单向数据传输)因为双向仅仅是重复
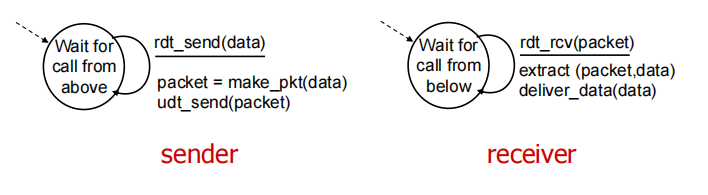
rdt1.0: reliable transfer over a reliable channel
完全可靠信道的rdf(假设底层信道完全可靠)
- underlying channel perfectly reliable
• no bit errors
• no loss of packets
separate FSMs(Finite State Machine) for sender, receiver
横线上是event横线下是action
独立fsm:
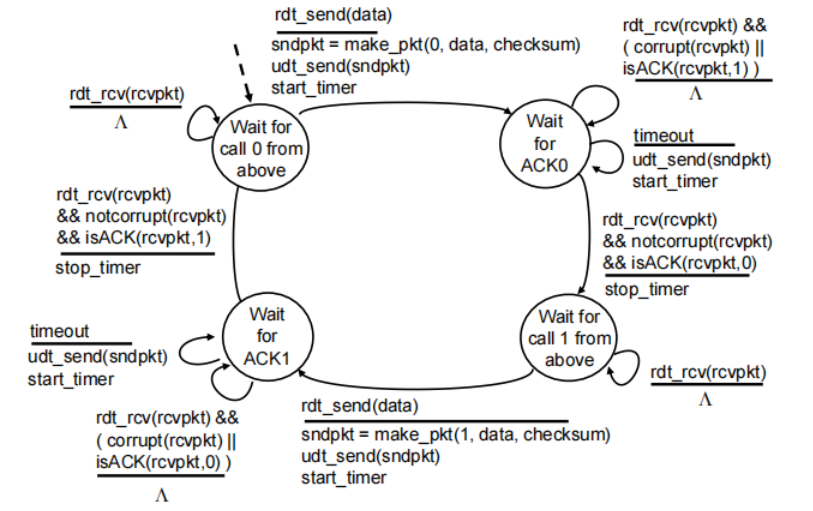
rdt2.0: channel with bit errors
underlying channel may flip bits in packet(下层信道可能发生bit受损)
• checksum to detect bit errors
• acknowledgements (ACKs): receiver explicitly tells sender that pkt received OK
• negative acknowledgements (NAKs): receiver explicitly tells sender that pkt had errors
• sender retransmits pkt on receipt of NAK(重传)
Sender(状态机上所有信息都是指某一方的):
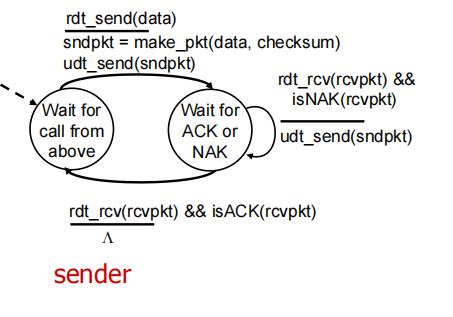
当reciver wait for call时,来了一个ACK/NACK ->do nothing(stop-wait)
receiver:
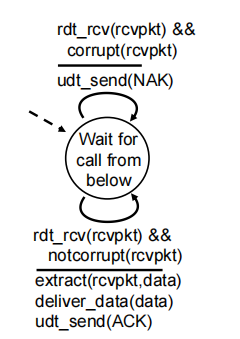
corrupt(rcvpkt)接收方发现分组损坏
fatal flaw: ACK/NAK corrupted,can’t just retransmit: possible duplicate (sender 发送完后等待ACK,此时reciver接收到data但是返回的ack在传输过程中corrupt,发送方被迫重传,造成duplicate)
handling duplicates:
▪ sender retransmits current pkt if ACK/NAK corrupted
▪ sender adds sequence number (seq) to each pkt编号防止重复
▪ receiver discards (doesn’t deliver up) duplicate pkt
sender sends one packet, then waits for receiver’s response
rdt2.1: sender, handles corrupt ACK/NAKs
sender:
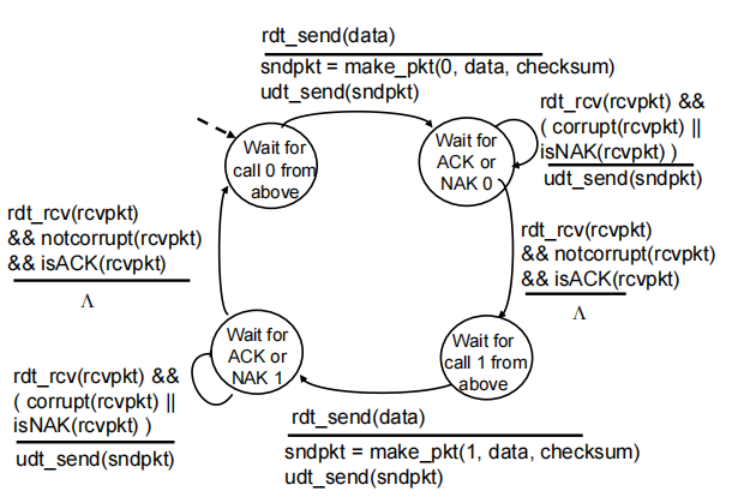
receiver:
为什么两个状态数(0 1)就足够?
只需要让发送发知道是在传last packet(seq same)还是 now packet(seq different)
receiver can not know if its last ACK/NAK received OK at sender
接收端无法确定ACK/NAK是否会被发送端接受,通过观察发送端的反应来判断它是否成功收到。
比如:本身应该wait for 1但是由于上一次接收端没收到ack,重新发数据(0)接收端发现发来的不是1,那就明白发送端当时收错了,所以发ACK回去,继续等待1.
只要接收到packet没有corrupt就发ack,不管序号是否正确
状态数量是前者两倍
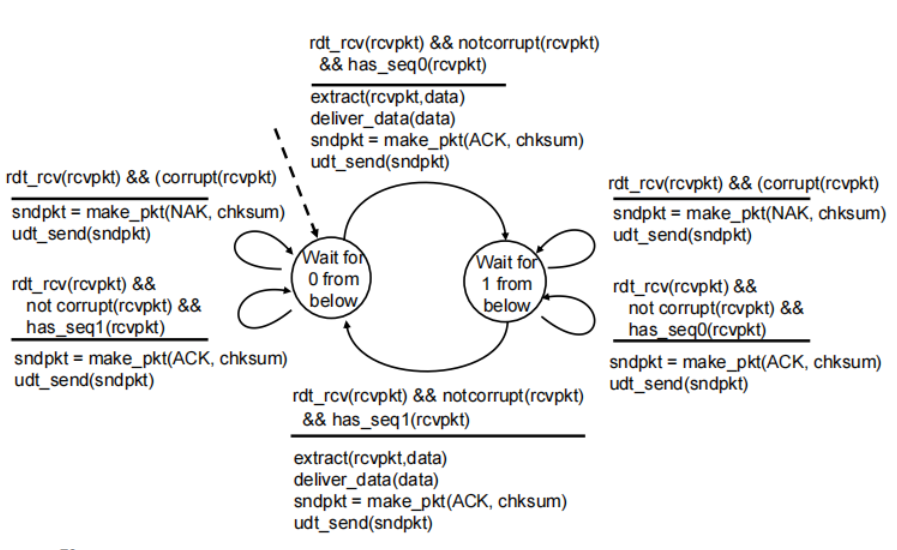
rdt2.2: a NAK-free protocol
▪ instead of NAK, receiver sends ACK for last pkt received OK
• receiver must explicitly include seq # of pkt being ACKed
不用NAK,而是用一个带序号的ACKA(上一个数据分组的序号)-确认上个分组收到了(没收到现在的分组)
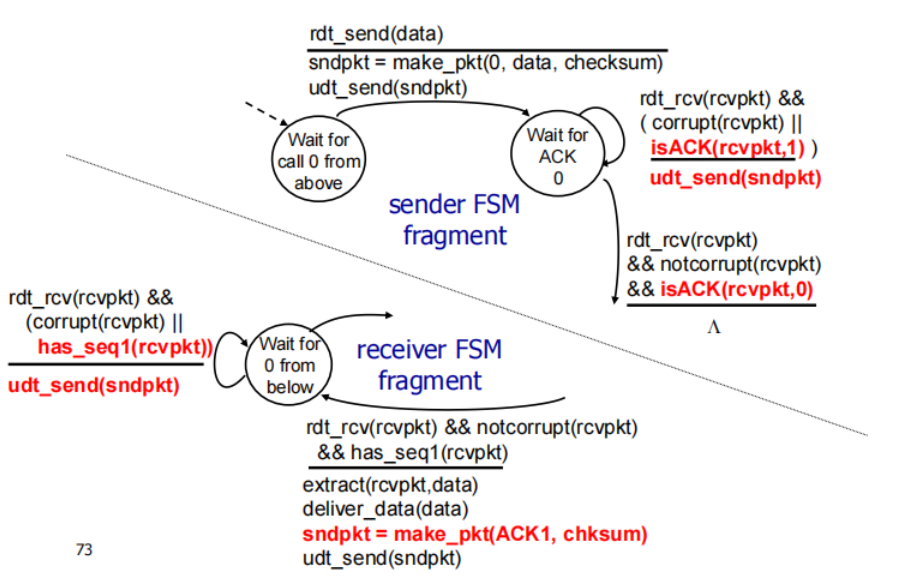
rdt3.0: channels with errors and loss
underlying channel can also lose packets (假设底层也丢包)
approach:
每发一个分组就启动一个倒计时计时器(cutdown timer) 当收到该分组的ACK或重发分组时重建一个计时器
sender waits “reasonable” amount of time for ACK
界定一个合理的时间,如果时间耗尽则界定为丢包——重发该分组
如果这个分组只是delay了(没loss)retransmission will be duplicate, but seq. #’ s already handles this
四种情况:
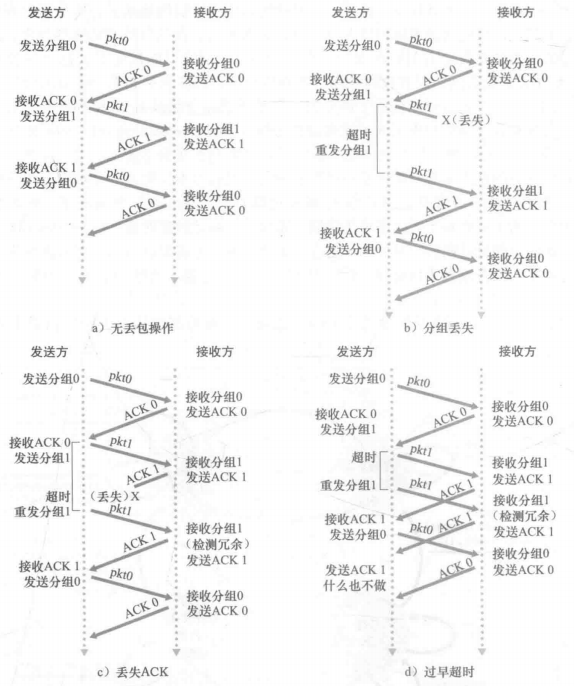
d接收到ACK1什么都不做(不重发)ppt有点问题
Performance of rdt3.0
3.0 rdt的性能
rdt3.0 is correct, but performance is very bad
Define round-trip-time as time to propagate there and back – (2 x end-to-end delay)
e.g.: 1 Gbps link, 15 ms delay, 8000 bit packet
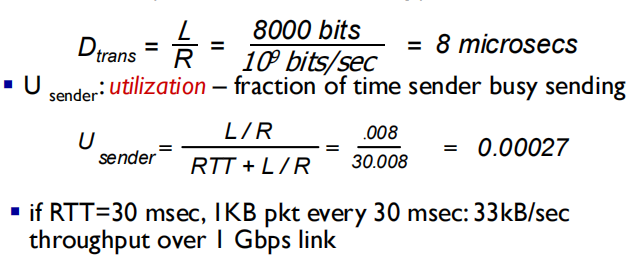
1Gbps的链路只能每秒发33kB数据,利用率很低

为了解决如上问题使用pipelined protocols不用stop-wait协议
Pipelined protocols
pipelining: Allows a sender to send more than one message at a time without receiving acknowledged
one after one
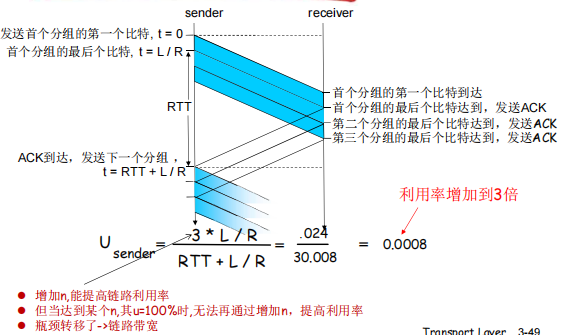
range of sequence numbers must be increased(每个输送的分组必须有唯一序号)
buffering at sender and/or receiver(缓存那些已经发送但没有确认的分组)(停等协议不需要buffer)
two generic forms of pipelined protocols: go-Back-N回退N步, selective repeat选择重传
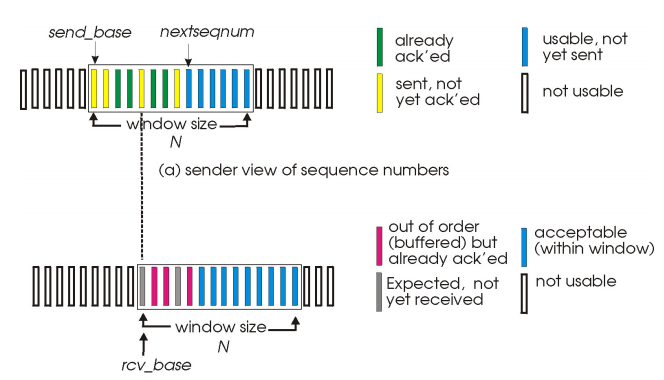
slide window流程
发送窗口N=1 接收窗口N=1 此时称为stop-wait
发送窗口N>1 接收窗口N=1 此时称为GBN
发送窗口N>1 接收窗口N>1 此时称为SR
滑动窗口(slide window):
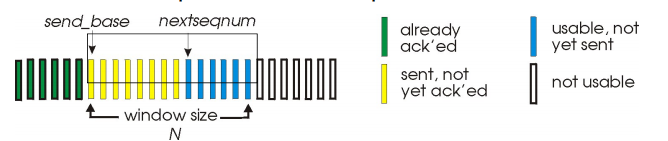
sender:
未发送任何数据:后沿=前沿 , 之间为发送窗口的尺寸=0
发送窗口的最大值<=发送缓冲区的值

上层传递一个分组,发送该分组但还没确认
前沿移动的极限:不能够超过发送缓冲区
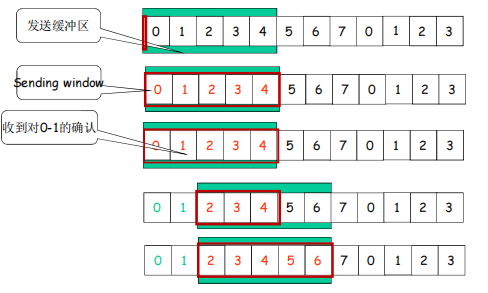
老分组得到确认
发送窗口后沿移动 :收到老分组的确认,不能够超过前沿
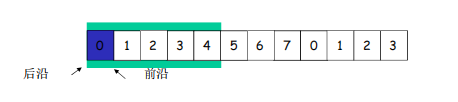
reciver
接收窗口用于控制哪些分组可以接收;
• 只有收到的分组序号落入接收窗口内才允许接收
• 若序号在接收窗口之外,则丢弃;
也就是说
接收窗口尺寸Wr=1,则只能顺序接收;(GBN stop-wait)
就一个槽位没法接收其他序号
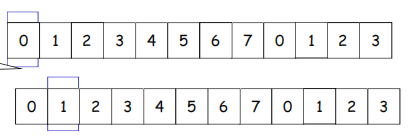
接收窗口尺寸Wr>1 ,则可以乱序接收
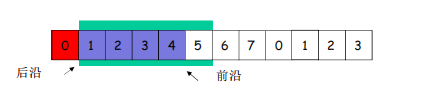
低序号的分组到来(0到来)接收窗口移动
如果高序号到来(1先到来)接收窗口不移动直到0到来直接移动到2(一起交付给上层)
(因为要实现rdt,不允许失序)
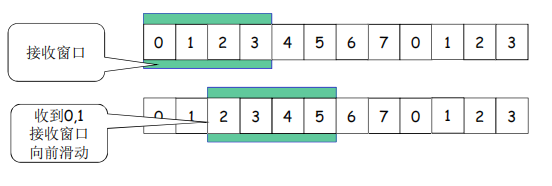
• 接收窗口尺寸=1 ; 发送连续收到的最大的分组确认(累计确认)
看上上图 :如果收到3仍然发送0的确认(表示没收到0,重发)
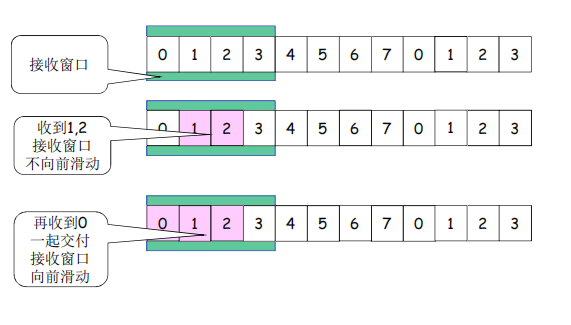
• 接收窗口尺寸>1 ; 收到分组,发送那个分组的确认(非累计确认)
收到几就发几



Go-Back-N
sender can have up to N unacked packets in pipeline
receiver only sends cumulative ACK(累计确认:当前序号的分组被acknowledged意味着前面所有序号的分组都被acknowledged)
累计确认:一个确认包确认了累积到某一序号的所有包,而不是对每个序号都发确认包。
分别确认:每个包都单独确认
doesn’t ACK packet if there’ s a gap(如果分组乱序:接收packet1->packet3,则不会acknowledge packet3,会返回packet2继续等待packet2)
sender has timer for oldest unacked packet(发送方对最早发出去的未被确认的数据有计时器,一旦此数据被acknowledged计时停止,如果超时则重发该分组之后所有已发送但未确认的分组,尽管有些序号更大的分组可能已经成功确认)也只有一个计时器
when timer expires, retransmit all unacked packets(重传所有未被确认的分组)
sender:
ACK(n): ACKs all packets up to, including sequence # n -“cumulative ACK(sender)”
• may receive duplicate ACKs (see receiver)
timer for oldest in-flight pkt
timeout(n): retransmit packet n and all higher seq # pkts in window
发送方只维持已发送但未被确认的最小序号
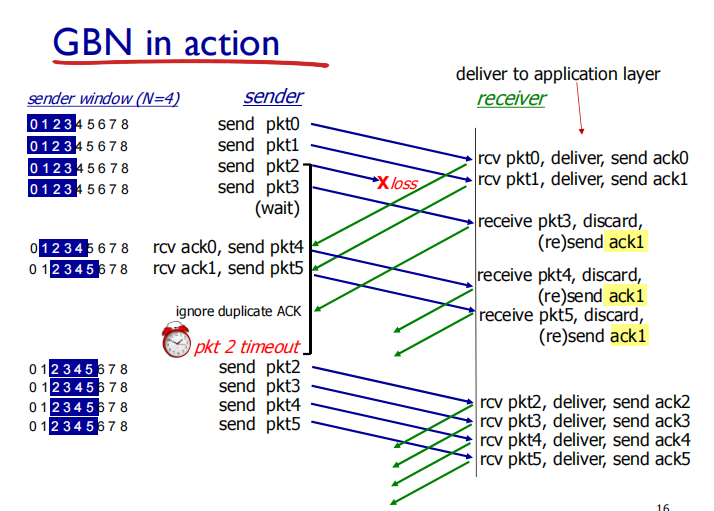
GBN:当发现N没发,就回到N,发N及之后的
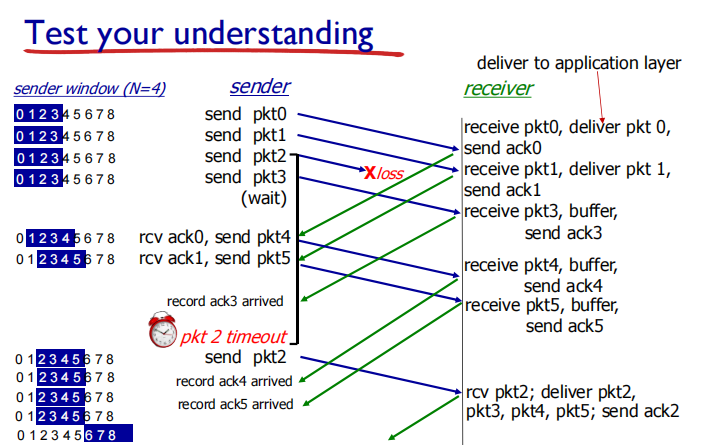
Selective repeat
sender can have up to N unacked packets in pipeline
Receiver sends individual ACK for each packet
buffers packets, as needed, for eventual in-order delivery to upper layer
sender maintains timer for each packet with no ACK
• when timer expires(到期), retransmit only that unacked packet(只重传没有确认的分组)
out-of-order: buffer
in-order: deliver (also deliver buffered, in-order pkts), advance window to next not-yet-received pkt
窗口长度必须小于等于序号空间大小一半
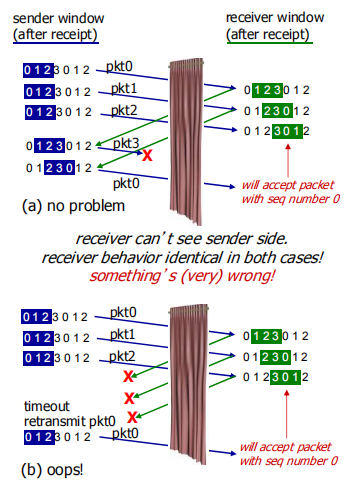
第一种情况:pkt3丢失,此时应该传第二轮的pkt0
第二种情况:ack0 ack1 ack2丢失,此时应该传第一轮的pkt0
但是这俩情况无法区分,所以窗口长度必须小于等于序号空间大小一半
TCP (Transmission Control Protocol)
TCP header
头部20B~60B
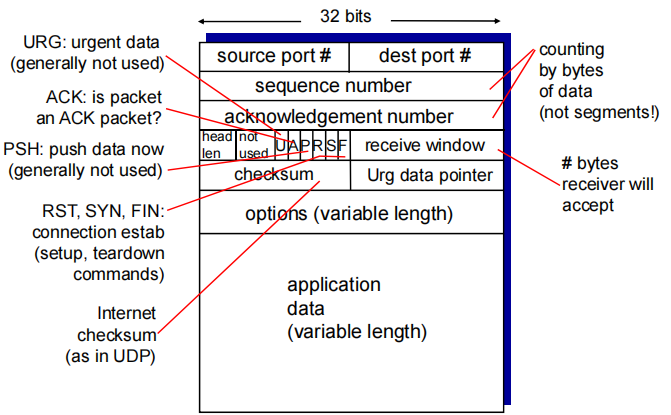
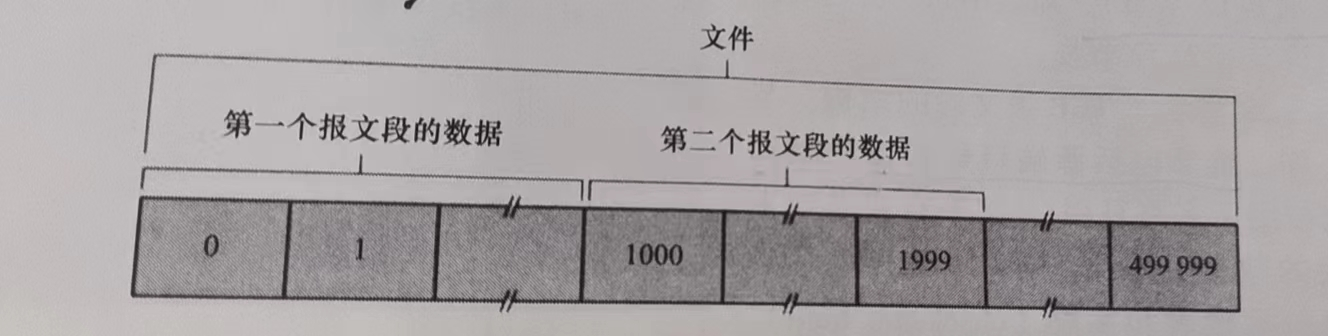
- sequence number:
• byte stream “number” of first byte in segment’s data
本报文段中第一个字节在字节流中的编号(0、1000)
- acknowledgements确认号:
•seq # of next byte expected from other side(cumulative ACK)
期望从另一方收到的下一个字节的序号(与rdt不一样)
how receiver handles out-of-order segments
如果以乱序到达,TCP没有规定一定要向GBN一样丢弃PKT,提供可编程实现的操作,可以丢弃也可以保留(后等待前面的到来)
注意区分seq和ack的不同,这里ack是期待的序号而不是本位序号
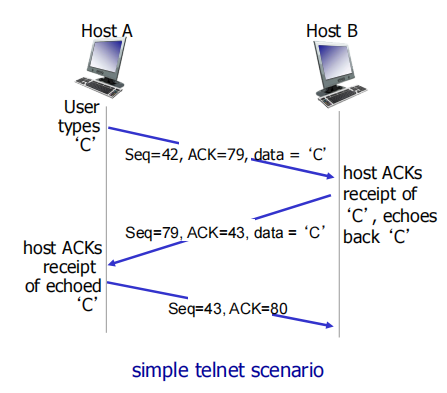
这个图是一收一发的过程:seq=上一个的ack, 但ack等于上一个seq+1
TCP round trip time, timeout
how to set TCP timeout value?
如何设置TCP超时等待时间,应该比RTT长,但是RTT随阻塞和负载情况变化
- longer than RTT
- but RTT varies
too short: early timeout, unnecessary retransmissions
too long: slow reaction to segment loss
how to estimate RTT?
SampleRTT: measured time from segment transmission until ACK receipt
SampleRTT will vary, average several recent measurements, not just current SampleRTT

exponential weighted moving average: 移动平均系统?dsp里那个
influence of past sample decreases exponentially fast 因为只想与最近的值有关(实时更新数据?)

timeout interval: EstimatedRTT plus “safety margin”
EstimtedRTT + 安全边界时间
• large variation in EstimatedRTT -> larger safety margin(变化大边界也设置大一点)
偏移量(实际值与平均值的偏移):



TCP不同于rdt中每个packet设置一个timer,tcp使用单一的重传定时器。
定时器只与最早的,未被确认的报文有关系
retransmission scenarios
- 丢包导致超时
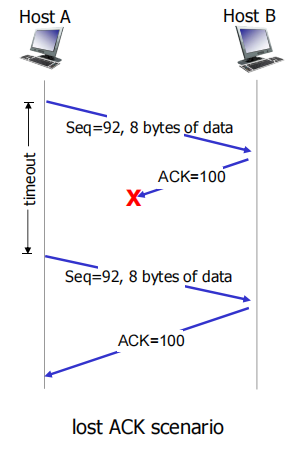
过早超时
此时报文段seq=100没有重传,因为在ack=100返回HostA时将再启动一个计时器,上一个计时器结束,这ACK=120在新计时区间里被找到,不用重传
定时器只与seq
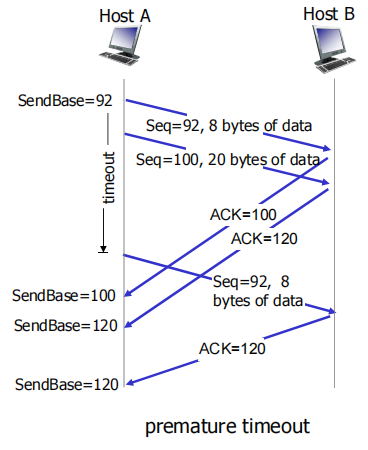
累计确认
当第一段报文在网络中丢失,但在超时前主机A收到120号ack,因为是累积确认,所以HostA知道Host B收到了119前的所有数据只会传120
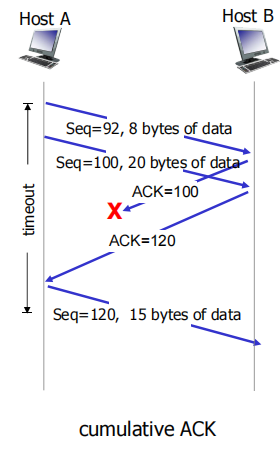
cumulative ACK像GBN
虽然ACK=100没到,但是ACK=120到了,那么sender知道reciver已经收到ack=100,这很像GBN
TCP fast retransmit
不等timeout就重传:
time-out period often relatively long:
• long delay before resending lost packet
detect lost segments via duplicate ACKs
if the segment is lost, there will likely be many duplicate ACKs(接收方反复期待)
if sender receives 3 duplicate ACKs(一共四个) for same data(“triple duplicate ACKs”), resend unacked segment with smallest seq#
三次冗余后才重传


TCP flow control
控制rwnd来控制发送发数据量,防止丢失
receiver controls sender, so sender will not overflow receiver buffer by transmitting too much, too fast
发送方根据接收方的处理能力来发送数据,不会导致接收方处理不过来,是流量控制(这是由接收窗口实现的)
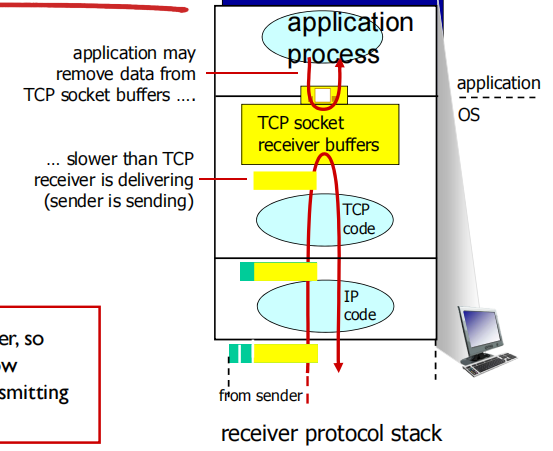
从TCP socket缓冲区中移走数据的速度比接收方交付数据的速度慢
receiver “advertises” free buffer space by including rwnd value in TCP header of receiver-to-sender segments
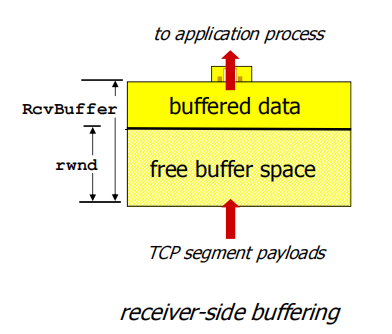
TCP通过发送方维护一个称为receive window(接收窗口)的变量(TCPpacket头部中一个变量)来提供流量控制,接收窗口用于告诉发送方,还有多少可以用于接收的缓存空间
rwnd = receive window
• RcvBuffer size set via socket options (typical default is 4096 bytes) 接收缓存
• many operating systems autoadjust RcvBuffer
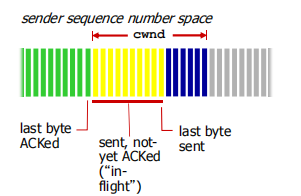
- sender limits amount of unacked (“in-flight”) data to receiver’ s rwnd value
guarantees receive buffer will not overflow
MSS and MTU
MSS (Maximum Segment Size最大报文长度) is a parameter specifying the largest amount of data in a single IP datagram that should be sent by a remote host.
报文段里应用层数据的最大长度
MTU is a parameter specifying the largest amount of data that a communication protocol or system can pass onwards. For example, standards (e.g. Ethernet) can fix the size of an MTU, or systems (such as point- to-point serial links) may set MTU at connect time.
MSS size is set according to MTU:
MSS = MTU – IP header size – TCP header size.


Nagle’s algorithm
问题:
TCP will send the data as it arrives at the send buffer if there is space left in the send buffer.
This means (for ssh/telnet) one packet sent every time user hits key.
Overhead of this is huge (TCP header + IP header + frame header to send one byte)
应用程序一次产生一字节数据,这样会导致网络由于太多的包而过载(一个常见的情况是发送端的”糊涂窗口综合症(Silly Window Syndrome)“)。从键盘输入的一个字符,占用一个字节,可能在传输上造成41字节的包,其中包括1字节的有用信息和40字节的首部数据。
Nagle’s algorithm
The sending TCP sends the first piece of data it receives – no matter no small or large
Sending TCP accumulates data in the buffer and waits until one of the following before sending the segment:
The receiving TCP sends an ACK
Data has accumulated to fill a maximum size segment (数据达到MSS)
Repeat step 2
当需要较快的交互/需要传递small pkt时不用Nagle’s algorithm
Silly Window Syndrome
糊涂窗口综合症是指当发送端应用进程产生数据很慢、或接收端应用进程处理接收缓冲区数据很慢,或二者兼而有之;就会使应用进程间传送的报文段很小,特别是有效载荷很小; 极端情况下,有效载荷可能只有1个字节;传输开销有40字节(20字节的IP头+20字节的TCP头) 这种现象。
发送端引起的糊涂窗口综合症
Sender produces data very slowly
接收端引起的糊涂窗口综合症
• Single byte or small number removed from full receive buffer.
• Sender is informed of opportunity to send small number of bytes and immediately sends filling buffer.
• Process repeats
接收端的TCP可能产生糊涂窗口综合症,如果它为消耗数据很慢的应用程序服务,例如,一次消耗一个字节。假定发送应用程序产生了1000字节的数据块,但接收应用程序每次只吸收1字节的数据。再假定接收端的TCP的输入缓存为4000字节。发送端先发送第一个4000字节的数据。接收端将它存储在其缓存中。缓存满了。它通知窗口大小为零,这表示发送端必须停止发送数据。接收应用程序从接收端的TCP的输入缓存中读取第一个字节的数据。在入缓存中有了1字节的空间。接收端的TCP宣布其窗口大小为1字节,这表示正渴望等待发送数据的发送端的TCP会把这个宣布当作一个好消息,并发送只包括一个字节数据的报文段。这样的过程一直继续下去。一个字节的数据被消耗掉,然后发送只包含一个字节数据的报文段。
解决办法– receiver does not advertise windows that would
**cause sender to send small amounts of data.**等buffer空间足够大再发送rwnd的值

Connection Management
连接管理 handshake
agree to establish connection (each knowing the other willing to establish connection)
agree on connection parameters
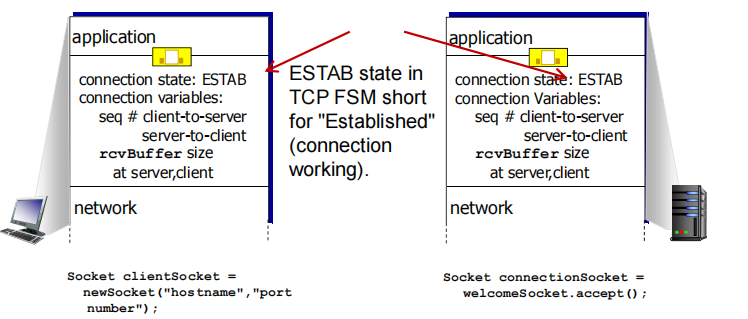
Q: will 2-way handshake always work in network?
variable delays
retransmitted messages (e.g. req_conn(x)) due to message loss
message reordering
cannot “ see ” other side
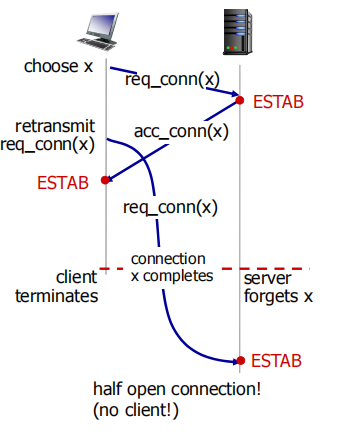
req_conn(x)第一次超时,导致重传,然而第一次发出去的req_conn(x)并没有丢失,而是回到sender,与之建立了连接,此时连接x已经完成。但是重传的req_conn(x)到达接收端后,再向发送端发送的ack被拒绝了也就是建立了half open connection持续占用资源
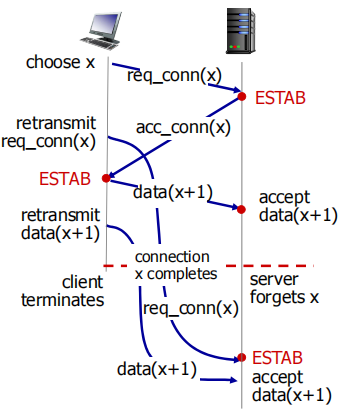
关闭连接后,发送方重传的报文才到达,此时server会误认为又新建一个连接,于是保持一个连接状态,但是client不这么认为(它知道是重传的)所以不会建立连接,白白浪费主机资源
TCP之三次握手和四次挥手 - 掘金 (juejin.cn)
深入浅出TCP三次握手 (多图详解) - 知乎 (zhihu.com)
TCP 3-way handshake
将小明当作客户端,小红当作服务器端,两人写信告白:
第一次握手:
小明告诉小红:我喜欢你。
第二次握手:
小红告诉小明:我知道了,我也喜欢你。
此时小红并不确定小明是否收到了告白信,直到
第三次握手:
小明回信:我也知道了,我们在一起吧。此时才真正建立连接。
(DHCP 也是这么个逻辑)
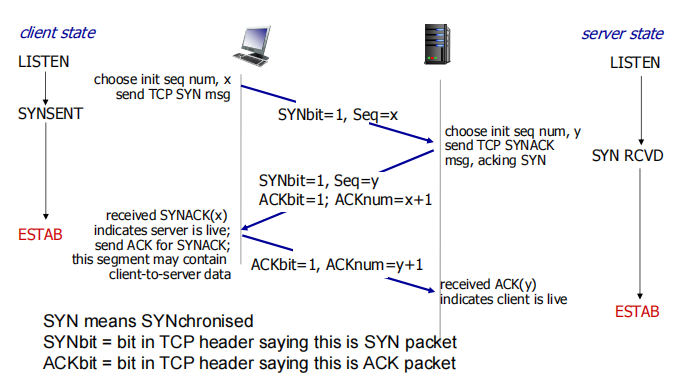
主机A发送位码为syn=1,随机产生seq number=x的数据包到服务器,主机B由SYN=1知道,A要求建立联机;
主机B收到请求后要确认联机信息,向A发送ack number=(主机A的seq+1),syn=1,ack=1,随机产生seq=y的包
主机A收到后检查ack number是否正确,即第一次发送的seq number+1,以及位码ack是否为1,若正确,主机A会再发送ack number=(主机B的seq+1),ack=1,主机B收到后确认seq值与ack=1则连接建立成功。
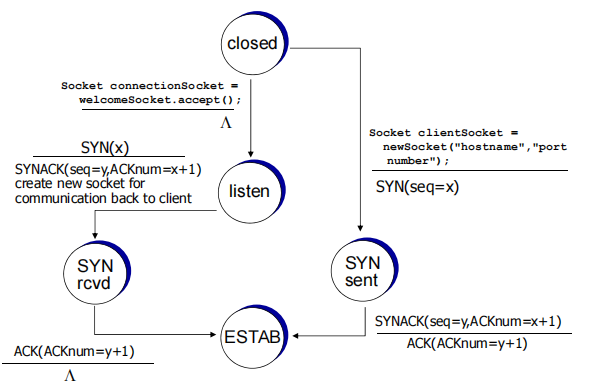
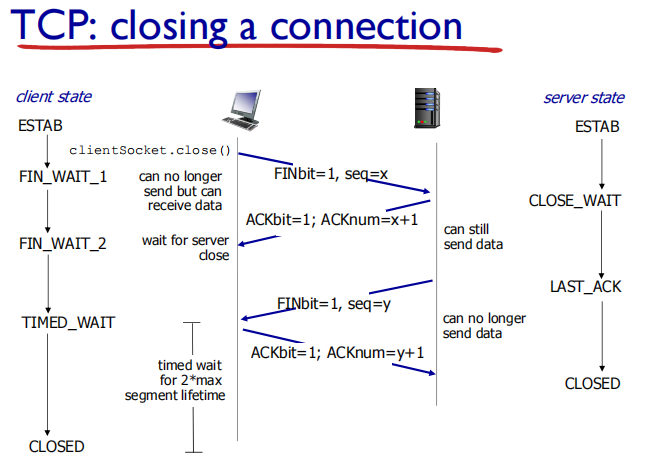
TCP: closing a connection 四次挥手
client, server each close their side of connection
• send TCP segment with FIN bit = 1respond to received FIN with ACK
• on receiving FIN, ACK can be combined with own FIN
simultaneous FIN exchanges can be handled
恋爱之后,小明和小红煲电话粥。依旧将小明当作客户端,小红当作服务器端。小明跟小红说话
第一次挥手:
小明说:我说完了。
第二次挥手:
小红说:好的,我知道了,我还没说完。
小红继续吧啦吧啦,说完之后
第三次挥手:
小红告诉小明:我说完了。
第四次挥手:
小明收到后告诉小红:好的,我知道了。等了2MSL之后小明挂断了。
如果此时小红说完,等了2MSL,小明一直不出声,这个时候就会重新说一次:我说完了。直到收到小明最后的回复,才挂断电话。

Principles of congestion control
congestion:too many sources sending too much data too fast for network to handle
- 表现为
• lost packets (buffer overflow at routers)
• long delays (queueing in router buffers)
- 原因(网络自身问题):
Too much traffic enters router – buffer fills up, this increases delay
Much too much traffic enters router – buffer overfills and causes loss. Packet needs to be retransmitted
If packet is lost after several “hops” then many resources are wasted. (e.g. Packet travels from A to B to C to D then lost at D – it has taken up space at A, B and C unnecessarily)
前面的流量控制是避免「发送方」的数据填满「接收方」的缓存,但是并不知道网络的中发生了什么。一般来说,计算机网络都处在一个共享的环境。因此也有可能会因为其他主机之间的通信使得网络拥堵。TCP 不能忽略网络上发生的事,它被设计成一个无私的协议,当网络发送拥塞时,TCP 会自我牺牲,降低发送的数据量。那么怎么知道当前网络是否出现了拥塞呢?
其实只要「发送方」没有在规定时间内接收到 ACK 应答报文,也就是发生了超时重传,就会认为网络出现了拥塞。
- goodput(实际吞吐量) – this is the rate at which data reaches the application layer. Different from throughput because of:
• loss
• retransmission
• corrupted packets
rwnd = flow control (not too fast for receiver)
cwnd = congestion control (not too fast for network)
TCP congestion control
congestion window由发送方主动调节
两种控制方式
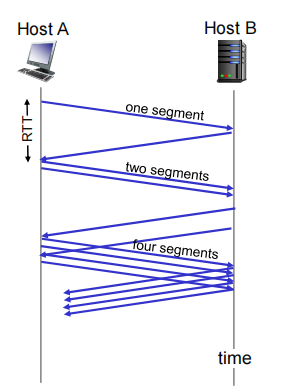
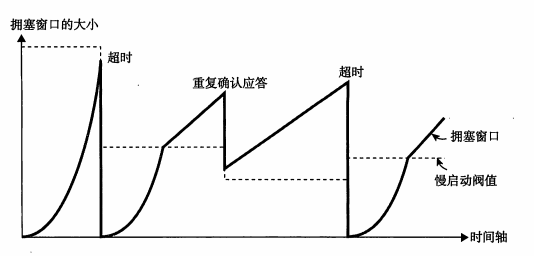
Slow Start
在TCP建立连接的开始:increase rate exponentially until first loss event
• initially cwnd = 1 MSS
• double cwnd every RTT
• done by incrementing cwnd for every ACK received(收到一个ACK cwnd×2)
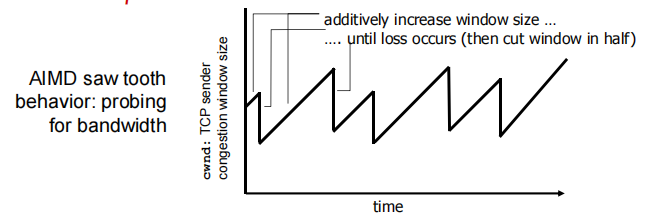
AIMD(additive increase multiplicative decrease)
加性增,乘性减
approach: sender increases transmission rate (window size), probing for usable bandwidth, until loss occurs
• Set cwnd – congestion window to initial value
additive increase : increase cwnd by 1 MSS(一个窗口大小) every RTT until loss detected
multiplicative decrease :cut cwnd in half after loss



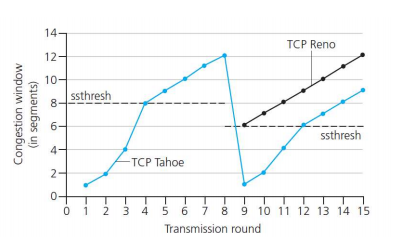
TCP Tahoe和Reno是处理TCP拥塞控制的两种形式(在三次冗余ack上有不同)
TCP RENO:
由于超时所引发的loss ,将cwnd设为1 MSS(重设threshold为上次丢包值的一半),重新慢启动至ssthresh慢启动门限,再使用AIMD
由3 duplicate ACK引发的loss cwnd减半然后线性增加(AIMD)
TCP Tahoe :
always sets cwnd to 1 (timeout or 3 duplicate acks)
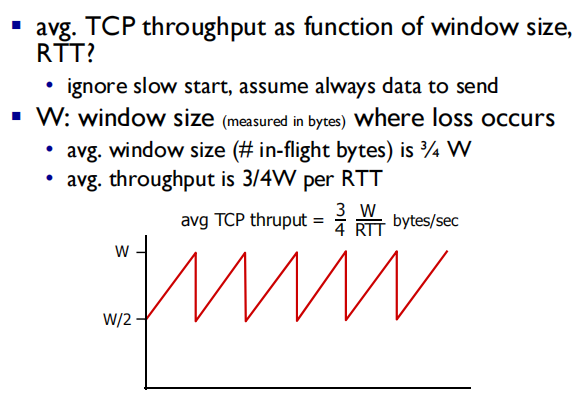
TCP throughput平均吞吐量
TCP Fairness
if K TCP sessions share same bottleneck link of bandwidth R, each should have average rate of R/K
TCP比起UDP来说需要在意网络拥塞的状态,而不是像UDP不管不顾的一直发送
application can open multiple parallel connections between two hosts
一个应用通常同时使用多个TCP连接(否则一直建立解除TCP效率太低了)
e.g., link of rate R with
9 existing connections:
• new app asks for 1 TCP, gets rate R/10
• new app asks for 11 TCPs, gets just over R/2





