
互联网应用笔记(九)
WWW (World Wide Web) Basics
WWW
World Wide Web: WWW, the Web, W3
技术上的定义:
- 使用HTTP协议,使用超文本hypertext呈现其内容
- W3C标准化组织给出了更广义的定义:可以通过网络访问的所有信息的集合,是人类知识的汇总(实现了互联网资源的整合,使用超文本,访问资源使用HTTP协议)
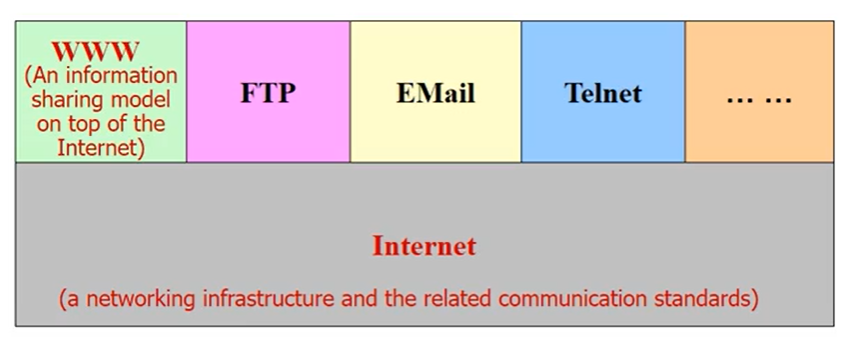
WWW和Internet不可以画等,他和其他协议一样都是属于互联网若干应用之一。
Internet代表的是底层的基础设置,WWW是上层应用
特点
- global 在任何地方只要连上互联网,就可以连接到3W进行资源访问
- open 开放,用户可以很容易的访问到/共享资源
- interactive 交互性 获取上传资源
- dynamic 动态的,网页越来越动态,会随着用户的访问情况动态生成内容
- platform-independent 对平台没有要求
- multimedia 多媒体越来越多
术语

- The Web: 一种信息高速公路,实现信息快速共享和访问
- URL:Uniform Resource Locator 用户通过URL访问特定的网页
- HTTP:HyperText Transfer Protocol 使用的传输的协议,用户可以通过HTTP访问WWW相应的资源
- HTML:HyperText Markup Language 网页使用的标记性的语言
WWW的构成
包含两大类Components:Structural Components、Semantic Components【语义成分】
Structural Components:
- client/browser 多种实现方式
- server/web-server 在功能强大的硬件上运行
- cache 有效提高访问效率,减少响应时间
- Internet——通过基础设施
Semantic Components:
- 传输协议HTTP
- 网页格式HTML
- XML (eXtensible Markup Language)
- URLs
The Web
信息高速公路
使用web将电子文档连成一张大的知识体系,让用户能够快速获得需要的资源
将分散在互联网中的数据连成一个information system 给用户提供相应的服务
客户端 browser,实现从web server 中得到HTML的文档,对其进行解析、展示
获取的文档也可以使用超文本hypertext link连接或者超链接,将的文档和信息资源整合到一起
HTTP是client和browser之间使用的传输协议,特性使得其能够支持新的数据格式
Web处于不断发展过程中,一方面将互联网中的资源在统一系统中整合在一起,随着技术发展,browser和server不断升级,支持的功能会有所偏差,所以在通信之前,cs之间要进行协商negotiation,使得他们能够用同样的数据格式进行通信。
Client端口
客户端就是用户常使用的browser;server端是存放所有数据的地方,通常在80端口browser和server之间使用HTTP进行数据的传输
基本浏览器属性
使用不同浏览器访问同一个网页效果不太一样,主要是因为各浏览器有不同的功能。(depending on their capabilities)
http:// 表示browser要使用HTTP协议与web进行通信
访问:点击超链接、输入URL
浏览器功能不仅仅是支持HTTP协议,除此之外还可以用FTP或者TELNET协议;因此除了访问webpage外,我们还可以使用浏览器来访问一些其他的资源,比如,email 或者文件系统,Telnet服务等等。浏览器功能强大
Server端口
远程软件,客户端发来请求就查询资源,并返回
一般在Unix或者Windows上运行
常见的webserver
基于==TCP==
一般使用**==80==端口**
通信过程:建立连接——request——response——释放连接;
早起HTTP:建立一次连接只做一次交互
所有的通信都要遵循HTTP协议规定
Web中所有操作都是stateless,server端不对访问进行记录
URLs
Uniform Resource Locators

使用URL指向特定的网页的地址,标识出网页的
- 协议
- 域名/IP地址
- 具体内容item
一般格式:
协议://网站的hostname或者IP地址[:端口]/在webserver文件系统中的文件目录/需要访问的内容现在的网站的资源基本上都是给出了客户端请求后动态生成的,实际上不是一个具体的静态网页,而是一个链接。服务器收到后会动态生成这个网页再返回。
URL结构

协议默认HTTP 端口默认80,没有写item会查找默认页面
URL中使用其他协议
除了HTTP其他协议在URL里面的使用

WWW标准
1. 三个主要的标准

- URL前面有 本次少讲
- HTTP:2616协议细节;2617协议认证功能
HTML
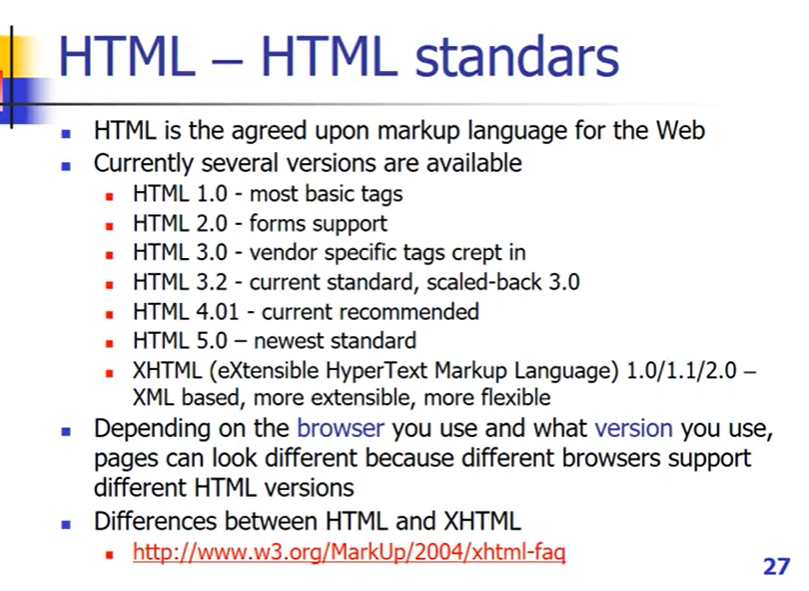
- 网页开发使用的标记性语言, 最新版本HTML5.0,解决了不同浏览器上不统一的问题
- XHTML结合XML和HTML,对数据格式作了扩展,浏览器支持的能力不一样。同样的HTML技术浏览器支持的版本也可能不一样,所以展示出来的形式功能也可能不一样。
静态与动态

- 最初,WWW由 静态的文件组成,每个URL对应着的都是硬盘上存储的单个文件,不会因为时间的推移、用户的变化而产生变化;后缀html htm
- 现在互联网WWW文档主要是采用动态方式的
- 用户请求过来后,实时生成页面内容,比如,淘宝购物搜索,然后动态查找生成
- URL不是指向单一的文件
- 假如通过网站访问计数器,计数器会因为访问的次数而发生变化,采用动态生成技术动态生成网页内容;后缀.asp, .shtm
- 动态页面对网站的发展有很大作用,统计访问者人数,广告的动态生成,数据库的访问,购物车
产生静态网页的过程
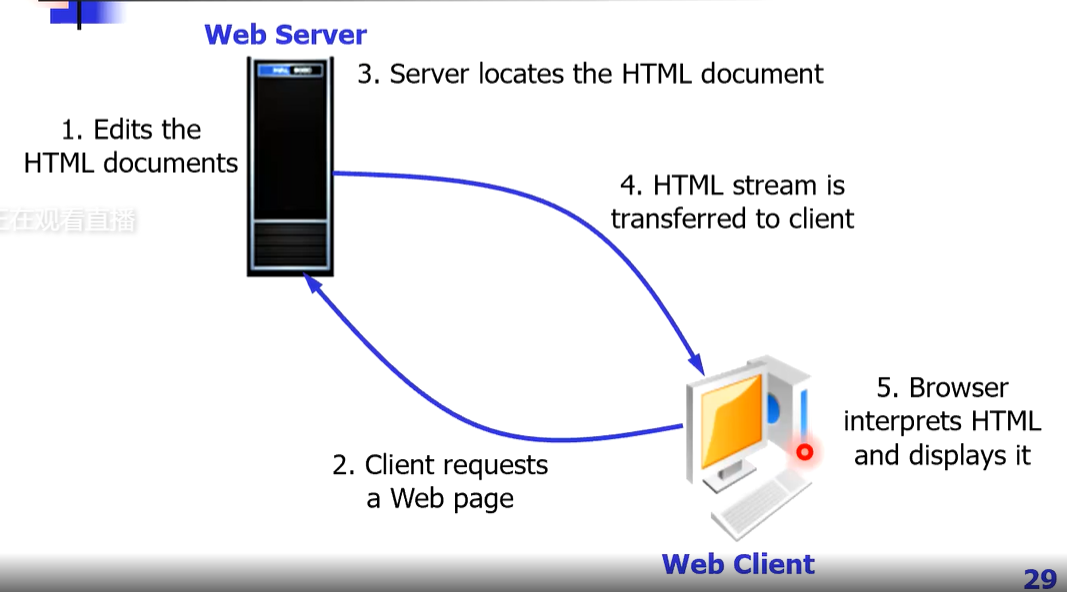
在webserver上开发人员设计了很多开发好的静态文档,webclient通过浏览器输入URL发给webserver请求特定网页,webserver收到后根据URL找到client所需的HTML文档,将文档发给client端,浏览器对文档进行解析和展示。因为是静态文档,所以对于不同的client,都是一样的
基于服务器产生动态网页
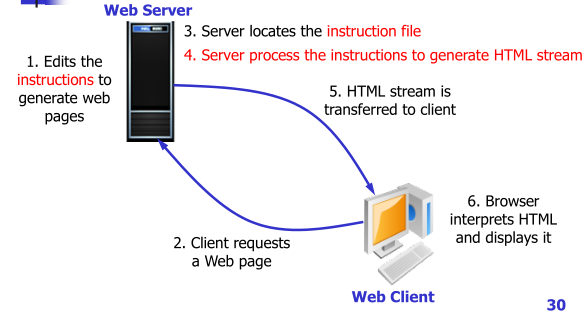
在webserver上会先设置一些动态生成网页的指令,webclient输入URL发起网页请求,server根据URL找到相应的指定指令文件,对指令进行解析(指令动态生成HTML文档,那么不同的客户端访问可能会对应着生成不同的文档流)webserver生成文档后将HTML转发给client端,浏览器解析展示
例子
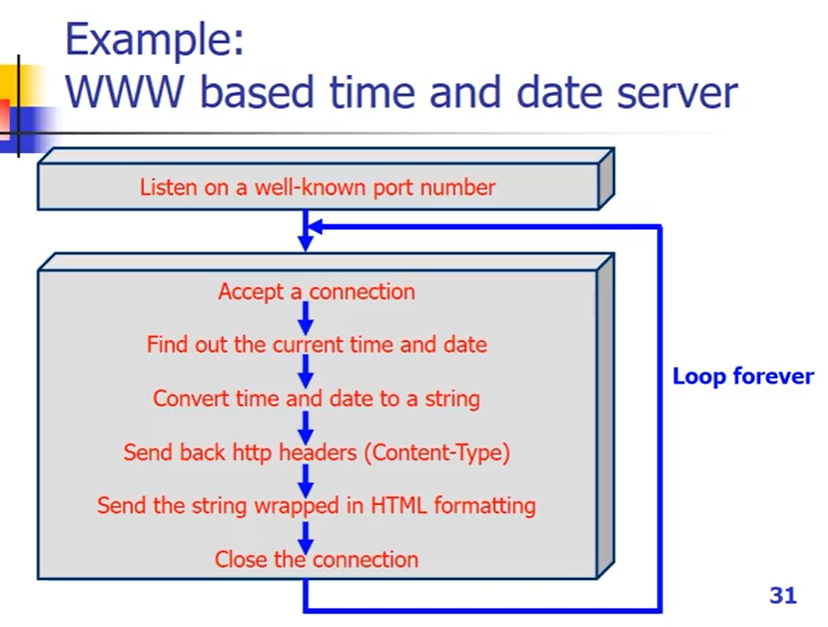
webserver在well-known port(80)上进行监听,client发来建立连接请求,server接收请求并建立连接;基于请求做相关的操作发给client端(获得系统时间,转换成字符串,发送报头,发送时间日期字符串,封装到HTML文档中,发送到client端),关闭连接
动态生成网页技术 CGI
Common Gateway Interface【通用网关接口】webserver和数据库间
通用网关接口(CGI)是将外部应用程序与信息服务器(如HTTP或Web服务器)连接起来的标准
Web客户机检索的纯HTML文档是静态的,这意味着它以不变的状态存在:文本文件不会改变。另一方面,CGI程序是实时执行的,因此它可以向服务器输出动态信息。
Web服务器执行一个CGI程序向数据库引擎传输信息,接收结果并将它们显示给客户机。这是一个网关的例子。目前的版本是1.1。
一个CGI程序基本上相当于让世界在你的系统上运行一个程序。为安全起见,采取安全防范措施。
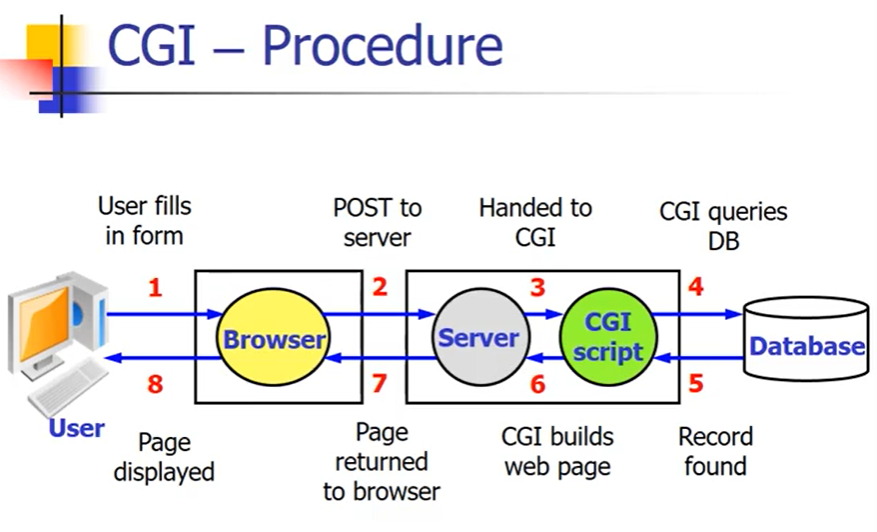
公共网关接口:实现了webserver和信息系统之间的接口,静态页面webserver存的是静态内容,client端请求的时候会发给client,内容不会发生变化,使用CGI程序之后,实时生成,所以每次产生动态信息,返回给client端
webserver收到请求——执行CGI程序——利用CGI传递给后台数据库——数据库上执行返回相应的结果——将结果返回给client端
gateway:实现“转发”的功能,相当于数据引擎,实现webserver和服务器之间的接口作用,当前版本号1.1,有时为了安全性也要采取一定的安全策略
CGI动态生成页面的过程:
HTTP
- Web应用的核心协议
- 特点:
- 应用层协议,基于client-server模型
- 基于request/response模式,client端发送request,server端收到后返回相应的response
- stateless:在HTTP这里,server端不会记录任何通信的历史
- 双向传输:双向同时发送信息
- capability negotiation:HTTP整体技术发展,导致其有多版本,client端和server端要在通信前进行技术的协商
- http代理过程中,要将获得的页面信息缓存才来,提高信息获取的效率
- 支持中间设备,HTTP proxy代理,通过代理的方式实现cs之间的通信,由proxy实现信息的转发
状态码

通信过程
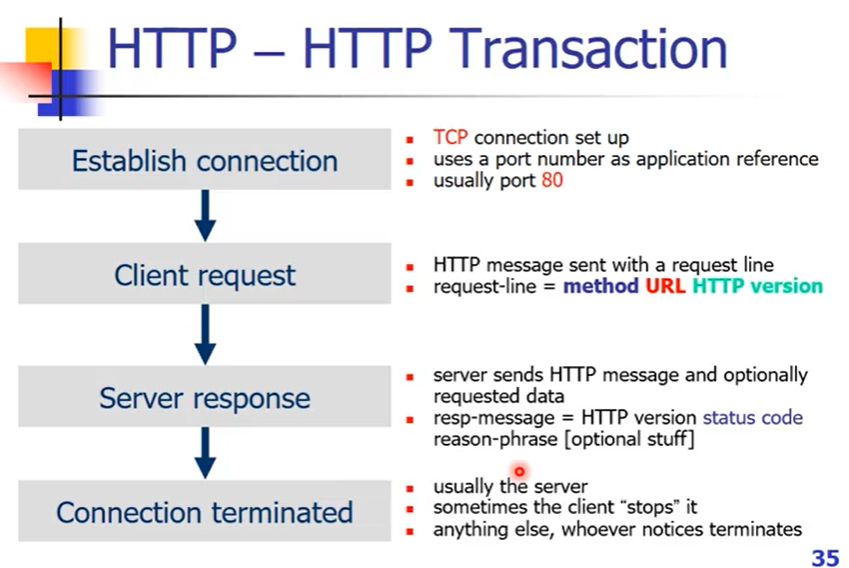
- 建立连接:三次握手建立TCP连接
webserver启动起来,在80端口进行监听
- client发送request:HTTP消息带有请求(HTTP method + URL + HTTP version)动作+URL+version
- server收到后返回response:封装成HTTP消息(version+status code[对命令的状态码,对命令的结果]+错误原因(如果有的话)),有可能带上需要访问的数据
- 连接断开:一般情况下由server中断connection
获取远程网页

- 浏览器识别URL
- 浏览器对URL(三部分)进行解析:针对域名,去DNS那里对其进行解析,然后将IP地址返回给浏览器,浏览器收到后想webserver IP地址发起TCP连接请求(socket方式)
- 连接建立完成后,会进入交互过程,browser发送get request(以下载页面为例,这时候只要第三部分信息即可)
- server找到对应的网页,将网页信息发回给client端
- release TCP connection
- 一次连接的建立后,只发送一次请求 一次响应,即一次交互,就会关掉连接
- 图片:第一次返回的时候不会返回图片信息,就只有HTML文本。浏览器解析的时候,会重新建立连接去下载图片(有多少张图片去重新建立多少次连接,一次连接只能请求下载一张图片)
HTTP常用方法
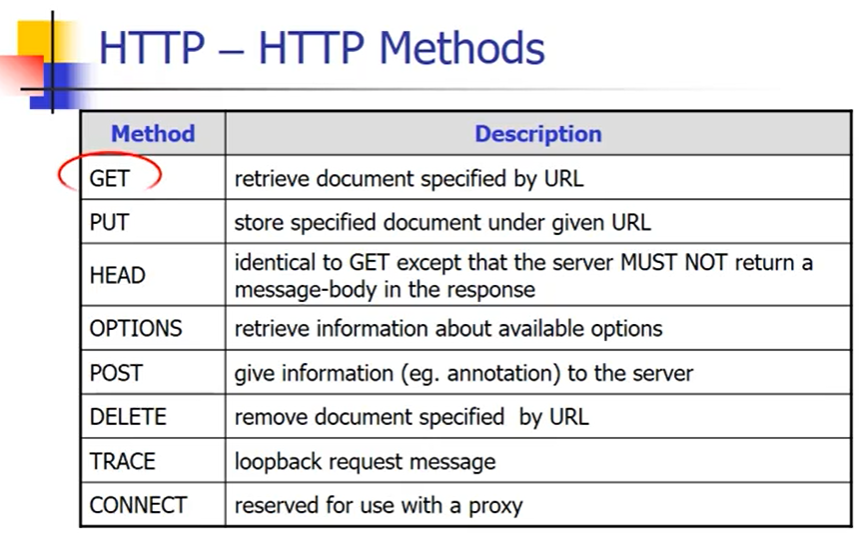
- GET:根据URL检索文档
- PUT:根据URL将本地文件上传到服务器上(需要特殊权限)
- HEAD:类似GET,但是不返回message,只返回头部内容
- OPTIONS:获取服务器选项功能
- POST:打开网页填写表单,将填写内容发给服务器,而不是将整个页面发过去。
- DELETE:删除页面(需要权限)
- TRACE:lookback ,跟踪一样的功能
- CONNECT:在特殊情况下使用,在访问过程中加入代理,client端通过connect和proxy建立连接
3.5 HTTP Request&Response 例子

- HTTP REQUEST:request line:跟client端发送的请求相关的命令,HTTP header(蓝色部分),HTTP body(一般在request里面不使用,没有实质的内容),中间要带上blank line(同email message)
- HTTP RESPONSE:response line(version+status code+解释)
- 4开头 错误解释
- 3开头 指向新的网页,需要进一步的动作
- 2开头 method执行成功,正确,加上blank line和相应的data
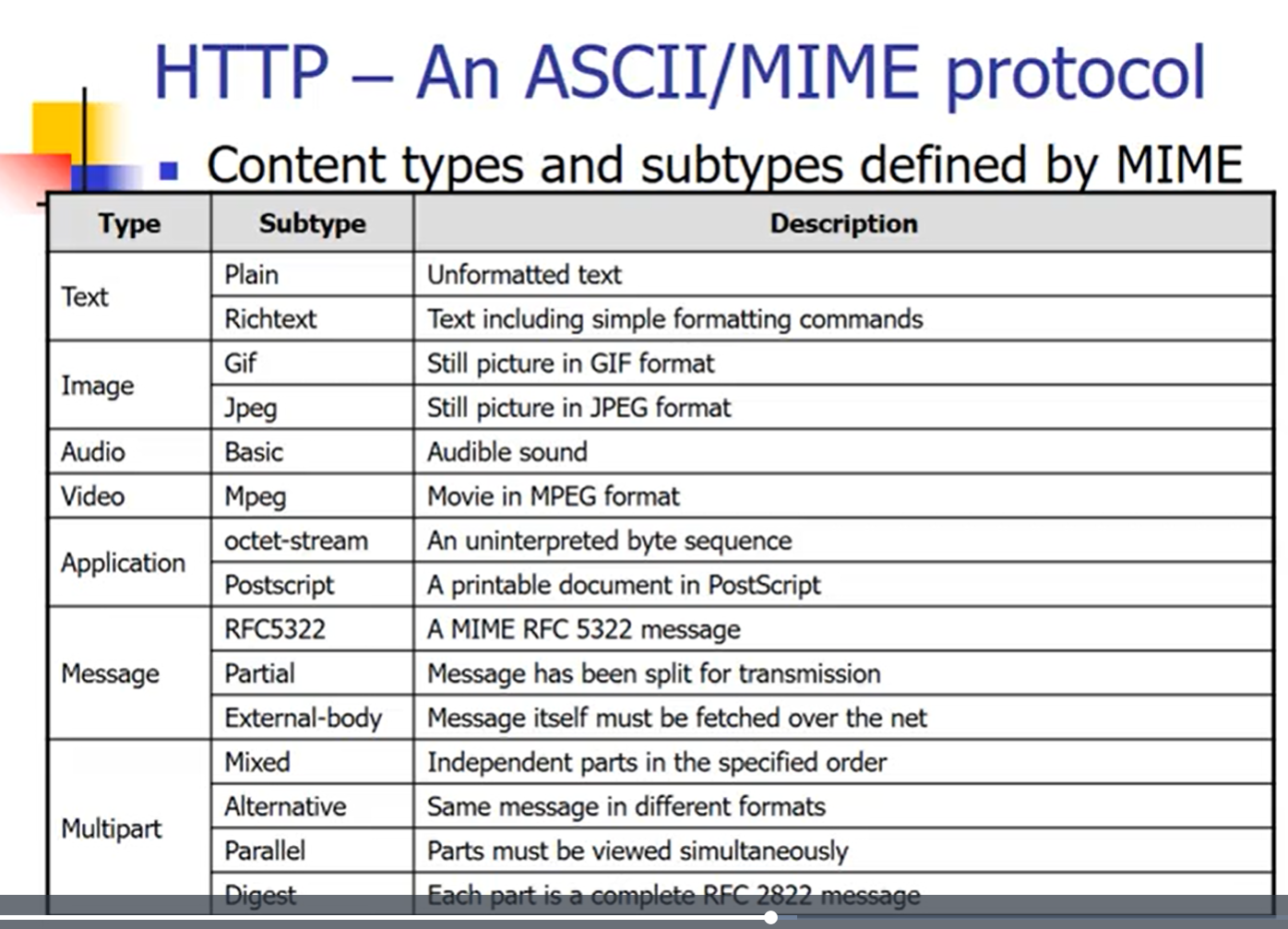
3.6 HTTP 一个==ASCII / MIME==协议

- 基于ASCII的协议,最初设计只能支持ASCII编码的文本文件,只能发送英文字符(一样在RFC522中定义)
- 后来也为了扩展功能,采用MIME的协议,将非ASCII转换为ASCII,在互联网上进行传输。
- MIME定义的内容类型和子类型
和 Email 很像
3.7 HTTP 1.1
目前HTTP版本使用的主要是1.0和1.1
- HTTP 1.0:停等协议(tfpt)
- client发送请求后就一直等,直到server端发来response才会去接着发送新的请求
- 每个文件都需要单独建立一个TCP连接进行发送,产生很多流量消耗,server也要维护很多connection
- HTTP 1.1
- 提高1.0的性能
- 持续性的连接/持久连接
- 管道通信方式 pipeline
- caching增强
- 支持压缩
- 提高1.0的性能
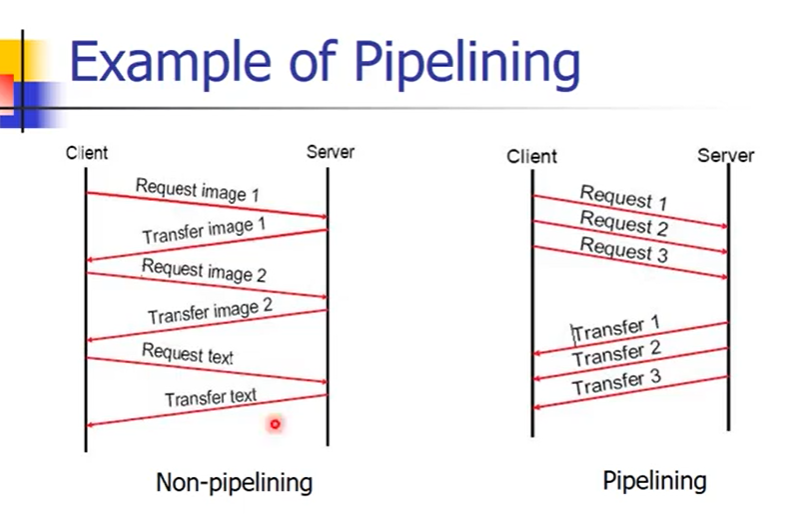
持续性的连接和管道通信方式
持续性的连接persistent connection:解决一个文件传输一个TCP连接的方式,建立连接可以在一个连接里发送多个数据,能够减少TCP协议建立和拆除过程中产生的数据包的数量。
管道通信方式pipelining:因为1.0 stop and wait,所以1.1为了改进,一次发送多个请求。这样可以批量发送请求和获得相应response,将多个HTTP request放到一个数据包里面,让server也能够批量处理相应的response回来
例子
HTTP 1.1 之前,不能在一个连接中传很多信息
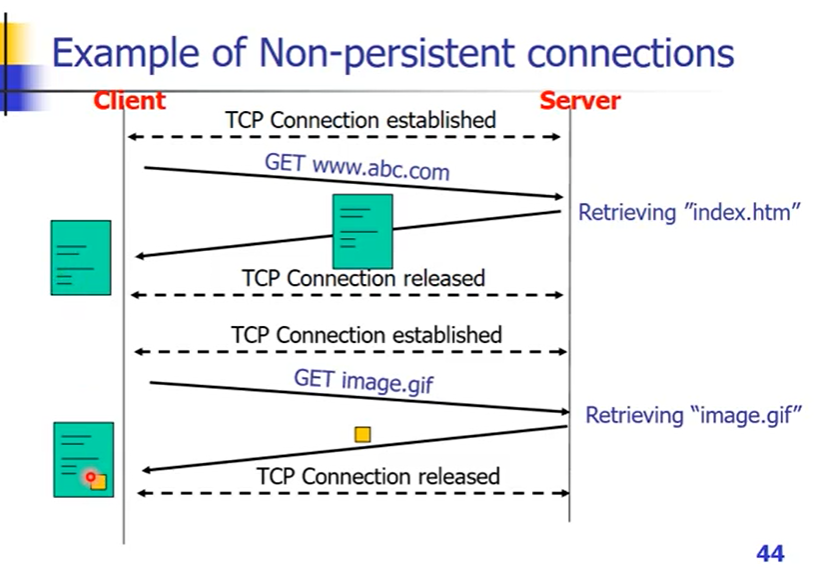
第一次:
第二次:再建立TCP连接,1个网页10个图片就要前后11次连接
对网络资源造成浪费
引入 HTTP 1.1 后

管道通信方式:一个报头多个消息
3.8 Cookies

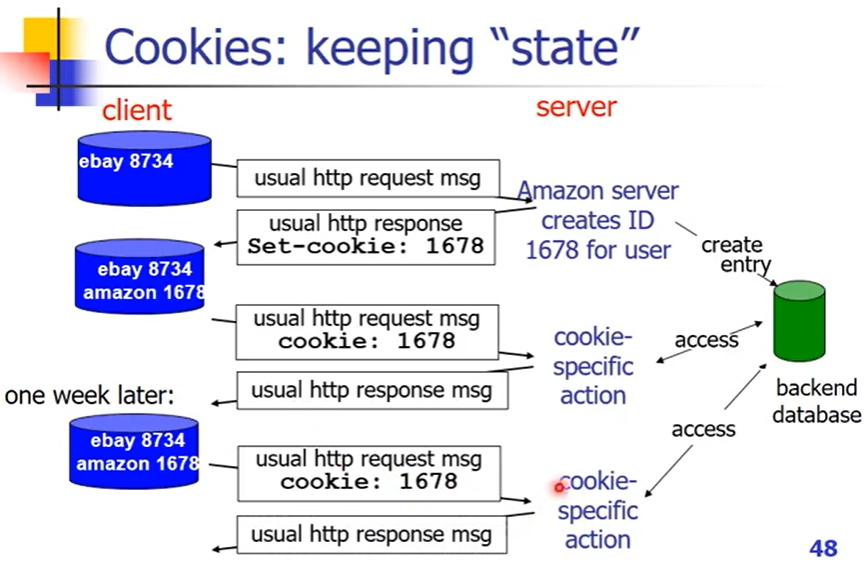
无状态:不保留任何客户端访问记录,没法提供个性化推送,不能通过IP地址识别用户
cookie创建过程:第一次访问某个网站,就会被分配某个ID(cookie),同时会在后台数据库为这个ID创建相应的记录。server在用户访问,发送HTTP请求的时候,会在server端HTTP响应的时候给用户发送一个id,用户会将cookie放在本地(浏览器管理)进行再次发送HTTP请求的时候,会带上cookie放在header部分,服务器端会根据cookie到数据库查找到相应的信息。
举例
四个组成部分:
- HTTP响应消息的cookie header line
- HTTP请求信息中的Cookie header line
- Cookie文件保存在user’s host上,由用户的浏览器管理
- 后端数据库位于网站上
使用Cookies来记录状态
3.9 Web Caches(Proxy Server)
代理服务器
- 主要目的:满足客户端访问的请求,不去与原来的服务器进行交互
- 用户设置浏览器:设置proxy server,由它连接web server,将相应信息转发回来
- 浏览器会把所有的HTTP请求发给proxy server
- 如果在cache里面有需要的文件,proxy server就会直接返回文件
- 如果没有,就会从原server里面请求,找到之后再返回给client端

上:没有的情况
下:有的情况
怎么让origin server内容和cache里面的内容一致?

conditional get 实现cache和origin server内容同步
server端发现cache内容在有限期范围内,就不回去返回内容,如果发现超出有效期,就会发response
对原来的get命令做一定的修改 在头部加上
If-modified-since:<date>
(有效期时间,缓存时间:如果在时间之后有改动cache内容就不是最新的,如果没有改动,就是最新的)
上:cache没有过期。request询问,response回复304 +status code(not modified),表明cache最新,可以使用,不用更新
下:cache过期。询问,返回modified,返回相应更新的内容。
3.10 HTTPS
==Hypertext Transfer Protocol Secure== (HTTPS)
使用安全套接字【SSL】或者TLS,在socket layer上面加了一项安全性,会对所有的负载信息(HTTP信息)进行加密,即使通过互联网传输,也无法解密
四、总结

